
Verbreitung von Programmiersprachen
Frage: Welche unterschiedlichen Programmiersprachen gibt es in Open-Source-Projekten und wie hoch ist der Prozentsatz jeder Sprache?
Beschreibung
Die Anzahl der Programmiersprachen und der Prozentsatz jeder Sprache in einem Projekt vermittelt ein gewisses Verständnis der Fähigkeiten, die von Code-Beitragenden erforderlich sind, sowie der Art des Projekts selbst.
Lernziele
Diese Metrik hilft Neueinsteigern in ein bestimmtes Open-Source-Projekt und bietet Open-Source-Programmmanagern eine Perspektive auf das Profil des Projekts im Kontext ihrer eigenen Erfahrung und Organisation.
- Diese Metrik kann von Entwicklern verwendet werden, um im Rahmen einer Jobsuche Projekte zu identifizieren, die stark von den von ihnen verwendeten Sprachen abhängen.
- Diese Metrik kann nützlich sein, um Änderungen in der Anzahl der Dateien oder Codezeilen in jeder Sprache im Laufe der Zeit zu identifizieren. Beispielsweise kann ein Projekt zu einem bestimmten Zeitpunkt zu X % aus Python und zu Y % aus Javascript bestehen. Vielleicht ein Jahr später kann die Menge an Javascript, gemessen an Dateien oder Codezeilen, größer sein, weil sich der Fokus eines Projekts auf die Benutzererfahrung verlagert hat.
- Diese Metrik kann mit Abhängigkeitsmetriken kombiniert werden, um festzustellen, ob in einem Projekt eine bekannte Sprache verwendet wird, für die jedoch noch kein Abhängigkeitsscanner identifiziert wurde.
- Wenn integrative, vielfältige und gerechte Gemeinschaften identifiziert werden, weisen sie ein gewisses Maß an Sprachverteilung auf.
- Wenn eine Person nach neuen Projekten sucht, an denen sie arbeiten kann, kann das Wissen, welche Projekte auf Sprachen basieren, die sie bereits kennen oder lernen möchten, einer von mehreren „persönlichen Filtern“ sein.
- Diese Metrik ist nützlich für OSPOs und Community-Manager, die verstehen möchten, welche Sprachen am bekanntesten sind und welche Sprachen vielleicht wenig verwendet werden, aber entscheidend sind.
Sytemimplementierung
Die Sprachverteilung berücksichtigt unterschiedliche Eigenschaften jeder Datei in einem Repository mit einer a priori identifizierbaren Computerprogrammiersprache. Wenn neue Sprachen auftauchen, kann es anfängliche Perioden geben, in denen Zählwerkzeuge ihre Erweiterungen nicht erkennen, in diesem Fall können sie als „andere“ gezählt werden. Solche Perioden sind typischerweise kurz.
Filter
- Uhrzeit
-
Anzahl der Dateien - Die Anzahl der Dateien jeder Sprache.
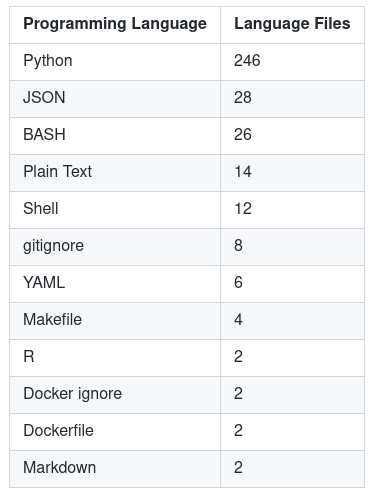
-
Codezeilen – Der Prozentsatz der Codezeilen für jede Sprache.
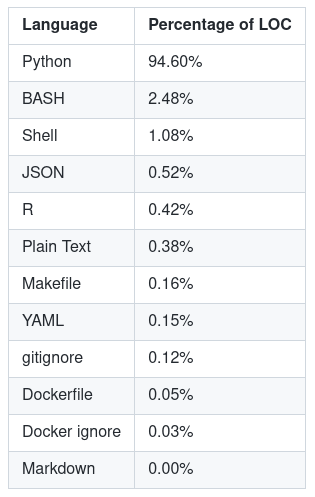
Je nach Anwendung der Metrik können entweder Codezeilen oder Dateien als absolute Zahlen oder Prozentsätze dargestellt werden. In vielen Fällen ist eine einfache Anzahl von Dateien nützlich, während die absolute Anzahl von Codezeilen schwer zu unterscheiden sein kann, da die Zahlen viel größer sind.
Tools, die die Metrik bereitstellen
Das Augur-Community-Berichte Das Repository stellt diese Metrik derzeit bereit
GrimoireLab stellt diese Informationen über den Proxy von Dateierweiterungen bereit
Augur stellt diese Informationen in seinem Frontend sowie über einen API-Endpunkt bereit.
Datenerfassungsstrategien
Der Inhalt eines Repositorys kann gezählt werden, indem jede Datei durchlaufen wird, obwohl mehrere Bibliotheken existieren, einschließlich der von Augur verwendeten: https://github.com/boyter/scc
Dateierweiterungen für einige Sprachen, wie z. B. Jupyter Notebooks, werden möglicherweise ausgeschlossen, da sie die tatsächlich verwendete Sprache verschleiern.
Bibliographie
Mitwirkende
- Morgenröte
- Beth Hancock
- Matt Germonprez
- Elisabeth Baron
- Daniel Isquierdo
- Kevin Lumbard
- Sean Goggin
Um diese Metrik zu bearbeiten, senden Sie bitte hier eine Änderungsanfrage: https://github.com/chaoss/wg-common/blob/main/focus-areas/contributions/programming-language-distribution.md
Um auf diese Metrik in Software oder Veröffentlichungen zu verweisen, verwenden Sie bitte diese stabile URL: https://chaoss.community/?p=3430
Die Verwendung und Verbreitung von Gesundheitskennzahlen kann zu Datenschutzverletzungen führen. Organisationen können Risiken ausgesetzt sein. Diese Risiken können sich aus der Einhaltung der DSGVO in der EU, der staatlichen Gesetze in den USA oder anderer Gesetze ergeben. Vertragsrisiken können sich auch aus den Nutzungsbedingungen für Datenanbieter wie GitHub und GitLab ergeben. Die Verwendung von Metriken muss auf Risiken und potenzielle datenethische Probleme untersucht werden. Bitte sehen CHAOSS Datenethik-Dokument für zusätzliche Anleitung.